在 理论篇 中,我们介绍了伴鱼在调用链追踪领域的调研工作,本篇继续介绍伴鱼的调用链追踪实践。在正式介绍前,简单交代一下背景:2015 年,在伴鱼服务端起步之时,技术团队就做出统一使用 Go 语言的决定。这个决定的影响主要体现在:
- 内部基础设施无需做跨语言支持
- 技术选型会有轻微的语言倾向
1. 早期实践
1.1 对接 Jaeger
2019 年,公司内部的微服务数量逐步增加,调用关系日趋复杂,工程师做性能分析、问题排查的难度变大。这时亟需一套调用链追踪系统帮助我们增强对服务端全貌的了解。经过调研后,我们决定采用同样基于 Go 语言搭建的、由 CNCF 孵化的项目 Jaeger。当时,服务的开发和治理都尚未引入 context,不论进程内部调用还是跨进程调用,都没有上下文传递。因此早期引入调用链追踪的工作重心就落在了服务及服务治理框架的改造,包括:
- 在 HTTP、Thrift 和 gRPC 的服务端和客户端注入上下文信息
- 在数据库、缓存、消息队列的接入点上埋点
- 快速往既有项目仓库中注入
context 的命令行工具
部署方面:测试环境采用 all-in-one,线上环境采用 direct-to-storage 方案。整个过程前后大约耗时一个月,我们在 2019 年 Q3 上线了第一版调用链追踪系统。配合广泛被采用的 prometheus + grafana 以及 ELK,我们在微服务群的可观测性上终于凑齐了调用链 (traces)、日志 (logs) 和监控指标 (metrics) 三个要素。
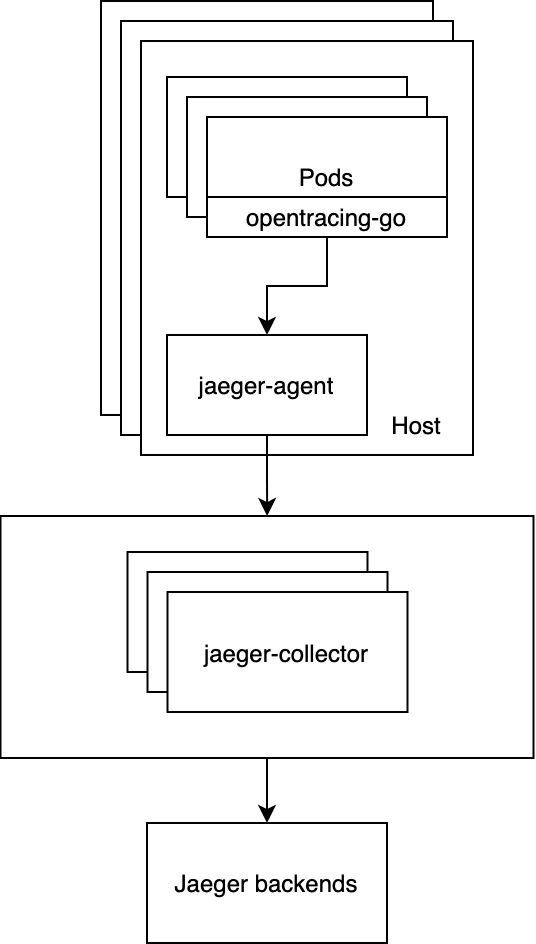
下图是第一版调用链追踪系统的数据上报通路示意图。服务运行在容器中,通过 opentracing 的 sdk 埋点,Jaeger 的 go-sdk 上报到宿主机上的 Jaeger-agent,后者再将数据进一步上报到 Jaeger-collector,最终将调用链数据写入 ES,建立索引,即图中的 Jaeger backends。