前言
可视化埋点,也称圈选埋点,是建立在全埋点技术基础上的一种数据埋点机制。通过全埋点技术,尽可能地将用户的所有交互行为进行采集上报,然后通过可视化圈选的方式筛选出感兴趣的行为统计数据,为产品运营提供决策支持。可视化埋点具有“全面、便捷、低技术门槛”的特点,能够有效降低研发、运营成本,是对传统代码埋点技术的有力补充。
本文结合伴鱼iOS端在圈选埋点技术上的一些实践经验,对圈选埋点方案的设计和实现进行探讨。
总体思路
从数据采集到生成统计报表,一般需要经过三个步骤,如下图所示
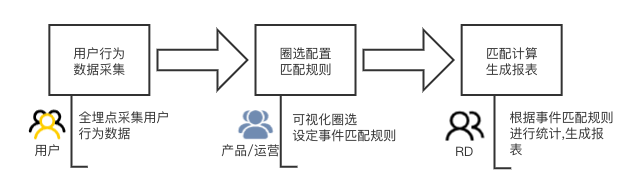
本文的缘起是回答知乎圆桌会议「分布式系统之美」的问题「如何系统性地学习分布式系统?」,后面稍微整理了一下,形成了这一篇文章(知乎 ID:kylin)。
学习一个知识之前,我觉得比较好的方式是先理解它的来龙去脉:即这个知识产生的过程,它解决了什么问题,它是怎么样解决的,还有它引入了哪些新的问题(没有银弹),这样我们才能比较好的抓到它的脉络和关键点,不会一开始就迷失在细节中。
所以,在学习分布式系统之前,我们需要解决的第一个问题是:分布式系统解决了什么问题?
第一个是单机性能瓶颈导致的成本问题,由于摩尔定律失效,廉价 PC 机性能的瓶颈无法继续突破,小型机和大型机能提高更高的单机性能,但是成本太大高,一般的公司很难承受;
第二个是用户量和数据量爆炸性的增大导致的成本问题,进入互联网时代,用户量爆炸性的增大,用户产生的数据量也在爆炸性的增大,但是单个用户或者单条数据的价值其实比软件时代(比如银行用户)的价值是只低不高,所以必须寻找更经济的方案;
微服务架构中,服务数量大大增加,调用关系变得复杂。用户的一个请求,会放大为内部服务间的若干次调用,依赖实际上变多了。而一个服务的故障,沿着调用链传播,也可能造成难以预料的影响。更糟糕的是,在服务数量很多的时候,故障是无可避免的。不论单个服务可用性达到几个 9,在服务数量 N 很大时,它的乘方一定会离 0 越来越近。在这种现状下,增强整体容错性就成为一项重要的工作。
一方面当下游服务挂掉时,上游服务作为调用方,需要有一定容错能力,设置一些兜底逻辑,尽量避免直接随之也挂掉。同时,也应避免无脑多次重试,降低下游服务的负载,使其有恢复的机会。
另一方面,作为服务本身,其资源是有限的,服务能力也是有上限的。对于超出上限的流量,只能忍痛丢弃。毕竟只服务部分请求,总比接收所有请求然后拖死整个系统要好得多
这两方面的考量,正是我们稳定性平台的主题:熔断与限流。网络上流传着一句话,熔断、限流、降级是分布式架构的三板斧,可见其重要性。
在进入文章之前,应该先介绍两位重量级作者:Andrew Pavlo 和 Matthew Aslett。Andrew 在 CMU 的计算机科学学院任教,主攻方向包括内存数据库、自动驾驶系统架构、事务处理系统和海量数据分析,他是 CMU Database Group 的核心成员,在 CMU 开设的两门课程 Database Systems (15-445/645) 和 Advanced Database System (15-721) 全是干货;Matthew 是 451 research: Data, AI & Analytics channel 的 VP,他在 2011 年的一篇 论文 中第一次用 NewSQL 指代提供类似 NoSQL 高吞吐、高可用支持,同时仍然保持 ACID 特性的新一代数据库系统。
相比于已经问世 40 多年的关系型数据库 (relational DBMS) ,我们不禁会问:”新兴的 NewSQL 究竟是一种市场营销还是确有其创新之处?” 如果 NewSQL 确实能够在多方面达到更高的性能,那么下一个问题就是:”它的性能是来自于硬件的升级还是其系统设计有着科学上的创新?”
要回答这两个问题,我们先讨论数据库系统的历史以及 NewSQL 的诞生,再讨论 NewSQL 在数据库系统各个重要设计方面的细节。
注:本文基本上会是原文的一个完整翻译,如果你愿意,大可直接点击文末链接翻看原文 :)
ID 生成器在前后端系统内都比较常见,应用场景广泛,如:订单 ID、账户 ID 、流水号、消息 ID 等等。常见的 ID 类型如下:
伴鱼内部也有很多 ID 生成的需求,像是我们的订单、支付单、一对一课程、绘本、 IM 聊天消息、账号等等。 ID 类型上也基本脱离不了上面几种,但是使用质量上参差不齐。
伴鱼少儿英语是目前飞速成长的互联网在线英语教育品牌之一,特别在疫情这段时间内,业务量增长近3-4倍。这期间,伴鱼慢日志系统对于帮助我们及时发现数据库性能问题、预防数据库性能风险和维护线上服务稳定性起到了很大的作用。
目前,伴鱼有10套TiDB数据库,20+套MongoDB数据库,近200+数据库实例。日常数据库性能问题处理,需要分析数据库慢日志,由于慢日志分散在多台机器,我们面临日志查询/分析/统计等各种不便。因此,我们设计了伴鱼慢日志系统并满足以下几个要求:
下面详细介绍下伴鱼慢日志系统设计以及系统给我们带来的实实在在的效果。
数据库监控作为数据库配套建设不可或缺的一环,可以及时发现机器和数据库性能问题,并帮助止损。伴鱼早期借助开源prometheus系统对数据库和机器进行监控,来满足我们日常的监控告警需求,但在这过程中,我们还是发现一些使用不太方便的地方,主要体现在以下几个方面:
基于以上监控告警需求,并结合在对prometheus、阿里云数据库监控等一些优秀的监控系统架构调研的基础上,设计了伴鱼数据库监控系统。相比其它监控系统,新系统包含以下核心功能:
下面从数据库监控整体架构详细介绍下监控各组件设计以及背后设计的一些想法。
随着伴鱼业务的快速发展,公司各产品线的业务不断丰富,日常的 SQL 上线也在不断增加。 SQL 审核与执行,作为 DBA 每天工作中相当重要的一环,如何保证 SQL 语句的质量,对于系统的高效运行和长久稳定有着很大的影响。
本文在对开源 SQL 审核平台(例如 Yearning、See 和 Archery 等)进行调研,并结合 DBA 在 SQL 上线实践经验的基础上,设计了伴鱼 SQL 审核平台。相比其它 SQL 审核平台,新系统主要包括以下核心功能:
下面从整体架构、流程设计等方面详细介绍下伴鱼 SQL 审核平台以及设计背后的一些思考。
I Heart Logs 出版于 2014 年,是一本很短小的书。作者 Jay Kreps,是前 LinkedIn 的 Principal Staff Engineer,也是 LinkedIn 许多著名开源项目的负责人及联合作者,如 Kafka、Voldemort 等。他是现任 Confluent 的 CEO,主要工作在于围绕实时数据提供企业级服务支持。这本书算是 Jay Kreps 过去多年实践的思考结晶。本文主要是对书中的一些看法、观点的梳理,有兴趣可以阅读原著或博客。
注:本文大部分图片、内容来自于原著或原博客。
在讨论日志之前,首先要明确日志的含义。这里的日志并非指我们常用的非结构化或半结构化的服务日志,而更接近数据库中常见的结构化的提交日志 (commit log/journal/WAL),这些日志通常是只往后追加数据,这里的序号暗含着逻辑时间,标识着连续日志产生的逻辑先后顺序:
随着公司业务的发展,数据量的持续增加,针对目前数据库基于TiDB 2.1使用过程中遇到的一些问题,例如:瞬间插入性能差,偶尔爆出insert的慢sql,select查询不能准确的使用合适的索引,数据量较大的集群Raftstore单线程压力的问题,以及考虑官方对2.1版本的优化和问题支持的滞后等问题,同时带着对3.0版本新功能和性能提升的期待,开始了tidb集群3.0大版本的升级之路。
正如DBA对数据库稳定运行的保障工作一样,TiDB进入3.0版本,官方在系统稳定性、易用性、功能、优化器、统计信息以及执行引擎做了持久的优化改进,稳定性和读写性能有了非常大的提升。
TiDB 3.0优化Raft副本之间的心跳机制,按照Region的活跃程度调整心跳频率,减小冷数据对集群的负担。优化了PD调度流程。新增Fast Analyze功能,提升收集统计信息的速度,降低集群资源的消耗及对业务的影响。其它特性还包括:SQL优化器的提升、支持窗口函数,悲观事务(从2.1升级后的版本依然是乐观事务,新部署的集群3.0.8以后支持悲观事务)、视图、分区表、SQL Trace等新特性。