随着伴鱼业务的快速发展,离线数据日渐无法满足运营同学的需求,数据的实时性要求越来越高。之前的实时任务是通过实时同步至 TiDB 的数据,利用 TiDB 进行微批计算。随着越来越多的实时场景涌现出来,TiDB 已经无法满足实时数据计算场景,计算和查询都在一套集群中,导致集群压力过大,可能影响正常的业务使用。根据业务形态搭建实时数仓已经是必要的建设了。伴鱼实时数仓主要以 Flink 为计算引擎,搭配 Redis ,Kafka 等分布式数据存储介质,以及 ClickHouse 等多维分析引擎。
伴鱼实时作业应用场景
基于平台提供了稳定的环境(统一调度方式,统一管理,统一监控等)。我们构建了一些实时服务,通过服务化的方式去支持各个业务方。
实时数仓:数据同步,业务数据清洗去重,相关主题业务数据关联拼接,以及数据聚合提炼等,逐步构建多维度,多覆盖面的实时数仓体系。
实时特征平台:实时数据提取,计算,以及特征回写。
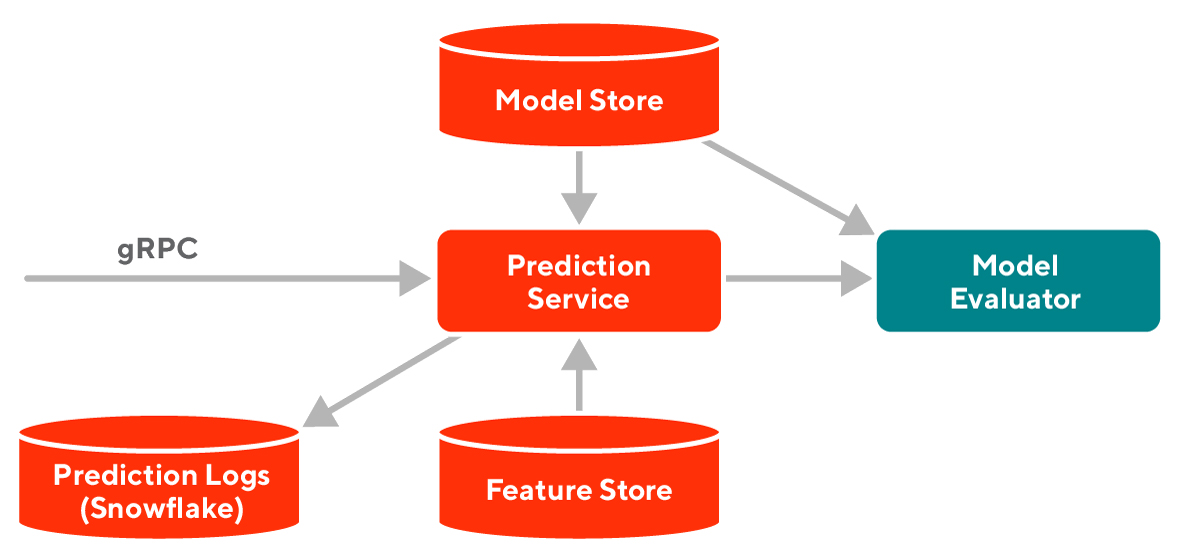
简单介绍下:目前数据在伴鱼内的流动架构图: