背景
伴鱼后端服务采用微服务架构部署,目前在服的服务有 800+。在 2019 年,公司就引入 Jaeger,
搭建自己的调用链追踪系统,目前每天写入的数据接近 100 GB / 天。但系统在实际生产使用中,依然不甚满意,主要症结在于:
- 系统采用头部连贯采样(head-based coherent sampling)的 Rate Limiting
限流采样策略,即在 trace 的第一个 span 产生时,就根据限流策略:每个进程每秒最多采 1 条 trace,来决定该 trace 是否会被采集。
这就会导致小流量接口的调用数据被采集到的概率较低,叠加服务出错本身就是小概率事件,因此错误调用的 trace 数据被采集到的概率就更低。 - 即使错误调用 trace 数据有幸被系统捕捉到,但 trace 上只能看到本次请求的整体调用链关系和时延分布,除非本次错误是由某个服务接口超时导致的,
否则仅凭 trace 数据,很难定位到本次问题的 root cause。 - 就算 trace 数据中能明显看到某个服务接口超时,但引发超时的并不一定是该接口本身,可能是该服务(或数据库、缓存等三方资源)被其他异常请求耗尽
资源,而导致本次请求超时。
本文将从「数据基础建设」、「深入挖掘分析」和「效果展示」三个方面,来介绍伴鱼是如何解决以上难题,并沉淀和固化自己的最佳实践。
数据基础建设
针对异常 trace 被采集的概率很低的问题,最容易想到的解决方案是对所有的 trace 数据进行采集,但这样做存储成本会很大,同时数据整体信噪比也会很低。
其实,该问题的本质就在于如何做到对异常情况下「有意义」trace 尽采,对其他 trace 少采。但,系统目前采用头部连贯采样(head-based coherent sampling),
在 trace 第一个 span 产生时,就已经对是否采集该 trace 做出了决定,并不能感知该 trace 是否「有意义」。 经过充分调研,
团队引入 OpenTelemetry 进行调用链通路改造,实现尾部连贯采样(tail-based coherent sampling)。
即在获取每一条完整的 trace 数据后,根据该 trace 是否「有意义」,再来决定采集与否。具体实施细节,请参考本文姊妹篇。
经过上述努力,异常 trace 被捕获的概率虽然得到提高,但 trace 中只有服务的上下游调用关系和时延分布。对于非接口超时,即业务逻辑错误导致的异常,
从 trace 上找不到问题的 root cause,需要联合调用链上的研发人员各自进行服务日志的详尽排查,才能找到问题所在。因此,团队对展示 trace 数据进行拓展,
添加「服务日志」标签,注入服务在本次请求中产生的相关日志,同时对存在异常的 span 添加「关注」标签,形成「调用链日志分析」功能,以便在系统中快速定位出本次请求的异常服务。
对于接口超时导致的异常,需要先排查接口自身可能的原因。若排除后,就需要进行服务上下游依赖的「深入挖掘分析」,找出可能被其他接口调用影响的原因。
其中的上下游依赖项既可能是服务也可能是一些三方资源(数据库、缓存、消息队列等),因此,团队在 RPC 框架中埋入服务上下游调用的监控指标apm_client_request_xxx{caller_service="caller_service",caller_endpoint="caller_endpoint",callee_service="callee_service",callee_endpoint="callee_endpoint"},
在访问三方资源的 SDK 中按照规范创建 span,
同时埋入服务访问的监控指标 sql_requests_xxx{caller_service="caller_service",caller_endpoint="caller_endpoint",cluster="cluster",table="table",command="command"}
(以数据库为例,其他类型三方资源的监控指标类似)。如此便可在产品实现的概念维度,将内部服务和三方资源等同处理(只是三方资源没有其下游依赖),
实现依赖链中上下游依赖项的「深入挖掘分析」。
最后,团队还在访问数据库的 SQL 语句中采用 comment 方式埋入请求 trace_id,
以便慢日志报警系统的报警文案中可以携带慢请求的 trace_id。
研发人员便可使用「调用链日志分析」功能,还原慢请求场景。详情可见后文「效果展示」。
深入挖掘分析
服务大盘
为了减少系统的接入成本,根据伴鱼多年实践,在服务初次上线时,便为服务创建一个默认的监控大盘。包括多个「监控面」,每个「监控面」包含多个「监控项」。
比如服务的「上游分析」「监控面」,就包括「上游请求 QPS」、「上游请求成功率」、「上游请求时延」等多个「监控项」。有了服务的「上游分析」和「下游分析」,
想要实现服务上下游依赖的「深入挖掘分析」,就需要在「监控项」的监控数据上内置「动作菜单」,实现服务依赖上下文的跳转分析。
为了实现「深入挖掘分析」,同时支持「监控面」的动态拓展,团队设计一套和页面的「交互协议」。在进入某个服务的监控大盘时,系统会根据协议返回页面中的「监控面」及其「监控项」,
以及「监控项」的布局和「动作菜单」数据,页面会根据协议数据进行页面绘制。绘制完成后,页面会根据「监控项唯一标识」,并发进行「监控项」的监控数据的拉取和渲染。
监控项唯一标识
为了实现上述「交互协议」,在系统后台中「监控项」采用「插件式」开发,「监控项」的「动作菜单」采用 Options Pattern 进行个性化配置。
「插件」的行为定义了「监控项」中监控数据的获取方式。
上文「数据基础建设」中有说到,在产品的维度,服务和三方资源是等同的。但在实现的维度,三方资源没有「下游分析」,而且其获取监控数据的方式亦与内部服务不同。
因此,系统将所有「插件」,按归属服务类型(内部服务、数据库、缓存、消息队列…)进行分组,同时采用「组合模式」,将「插件」组成一颗具有三层的「查询路由树」。
页面采用「监控项唯一标识」进行数据拉取时,通过「查询路由树」便可找到其「插件」实现。通过「插件」的定义行为,便可获取到监控数据。
看板和监控配置
上文中默认初始化创建的「服务大盘」,只包括一些服务工况的实时监控。有些业务指标维度的监控,就需要在「看板」内进行配置,类似 grafana 操作。
同时,系统默认在「监控项」中添加「配置报警规则」的「动作菜单」,用户利用菜单,选择监控类型(是否为同比),填写对应的监控阈值(极大值或极小值),
系统会根据用户点选的监控数据背后的监控指标,自动生成报警规则,下发「报警平台」。详见下文「监控报警可视化配置」。
效果展示
日常巡检和挖掘分析
系统支持「插件化」开发和配置「巡检项」,后台会每隔单位时间对「巡检项」进行巡检一次,并记录巡检结果。在页面上,单位时间的巡检结果,依据「巡检项」的安全阈值配置,
被划分为健康、亚健康、危险三个等级,同时依据等级,对巡检结果进行不同颜色的着色,形成单位时间巡检结果的「色块」。将所有「巡检项」的多个单位时段的巡检结果「色块」,
按时间维度进行排列,就形成服务日常巡检的「健康色谱」。
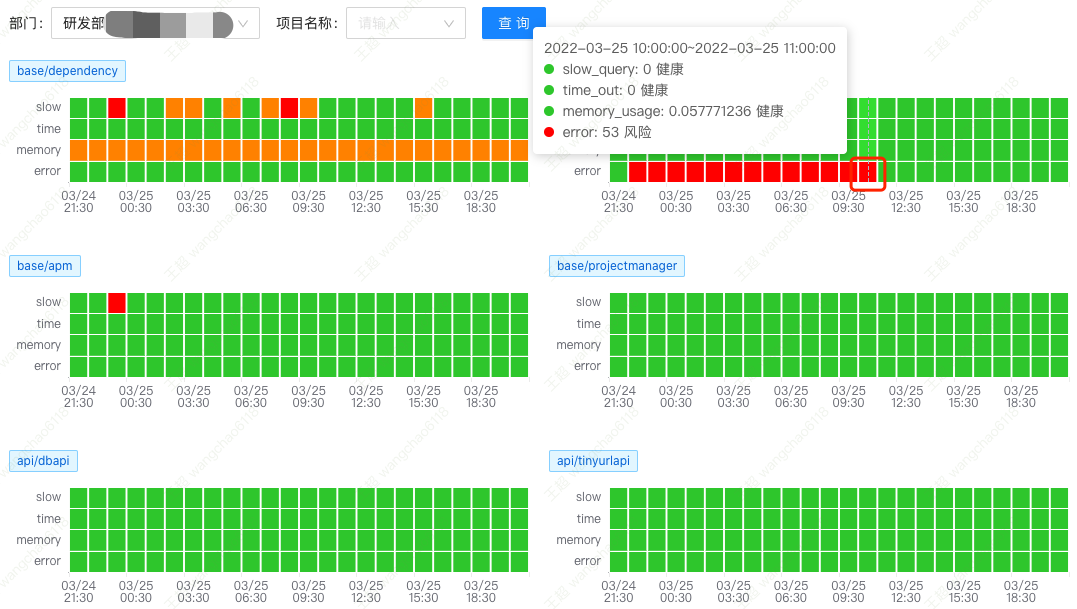
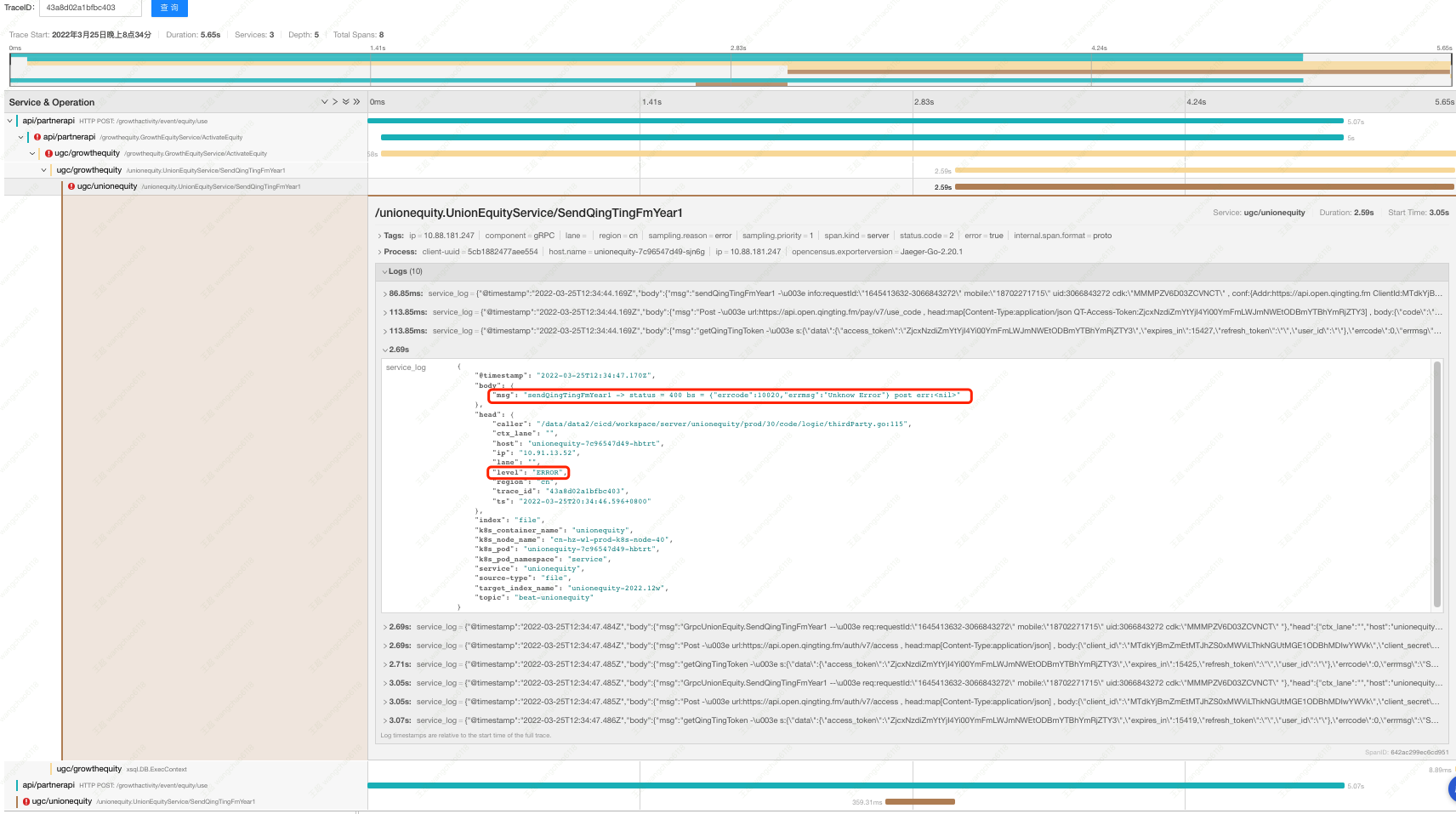
上图为进行部门服务日常巡检的工作页面,可以看到第二个服务的错误次数较多,红框选择「色块」所在时段的错误次数达到 53 次。点击该「色块」,进行问题的「挖掘分析」。
跳转到该服务在此时段的工况详情。
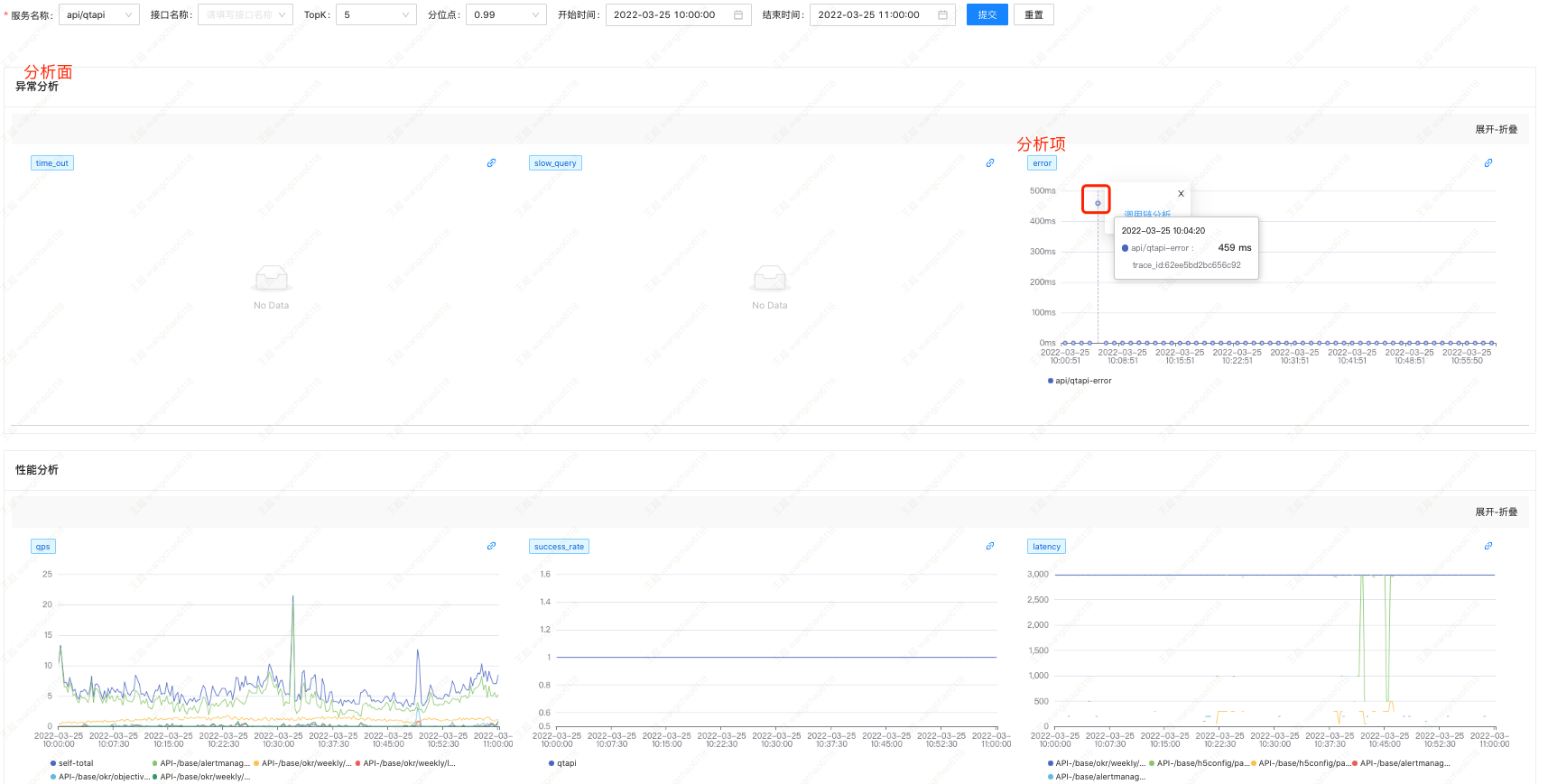
查看图中红框选择的散点,图签说明此次错误请求的耗时为 459ms,hover tips 提示本次请求的 trace_id 为 62ee5bd2bc656c92。点击该散点,弹出「动作菜单」,
选择「调用链分析」,跳转到「调用链日志分析」。
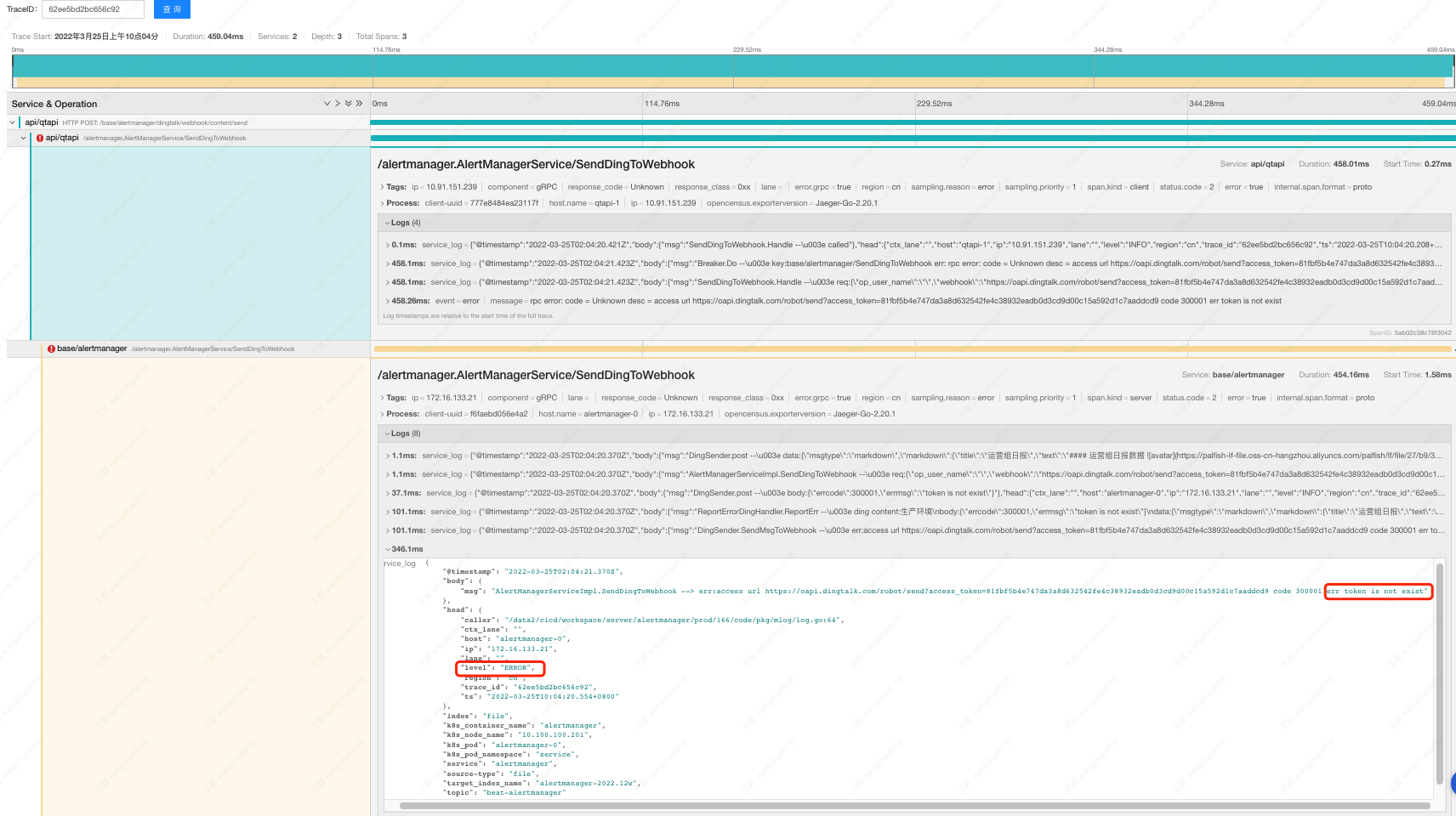
图中能清晰看到此次请求的调用链,以及相关服务在本次请求中的日志。找到最底层带有「关注」标签服务的 ERROR 日志,就基本明确了本次异常的 root cause。
调用链日志分析
报警平台机器人在发送报警文案时,会携带本次异常请求的 trace_id。
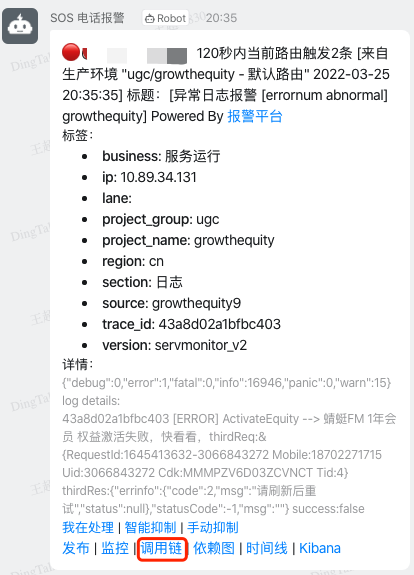
点击上图中「调用链」链接,即可跳转到系统的「调用链日志分析」,采用同样方式也能快速找到本次报警的 root cause。
监控报警可视化配置
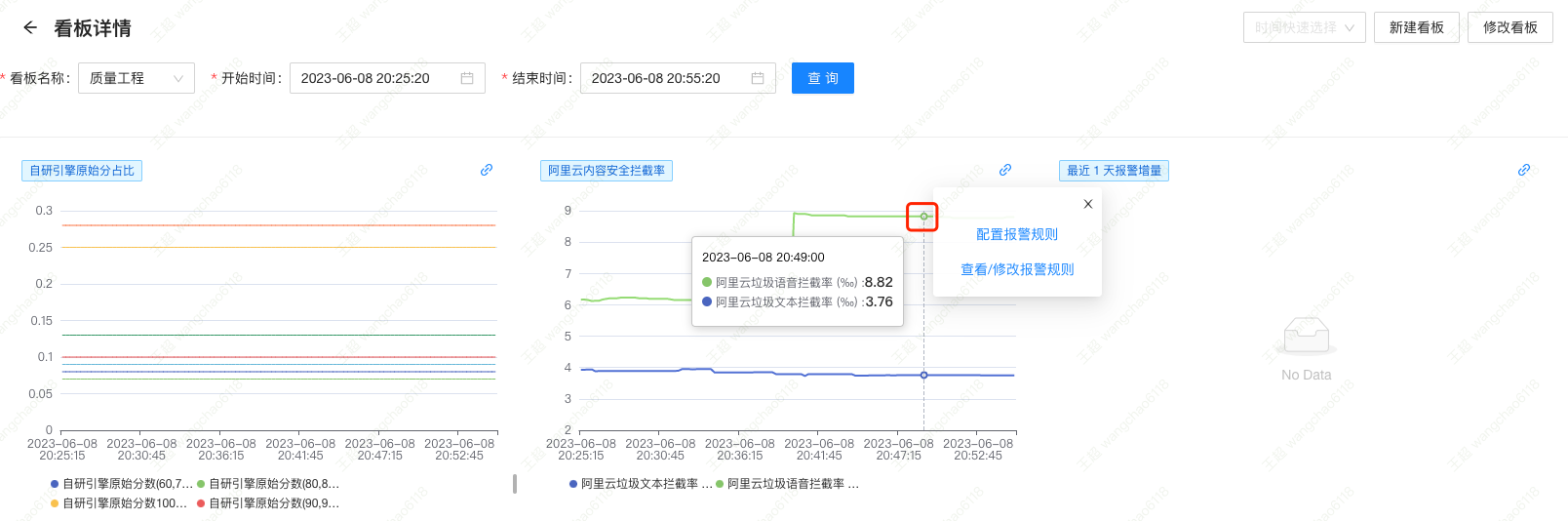
上图为「阿里云内容安全拦截率」的业务指标「看板」监控图。假如现希望对「阿里云垃圾语音拦截率」建立监控,当拦截率大于千分之 20 时,说明此刻有人在进行
“恶意”输入,需要告警给相关人员。点击该指标的任意数据点,在弹出的「动作菜单」中选择「配置报警规则」。
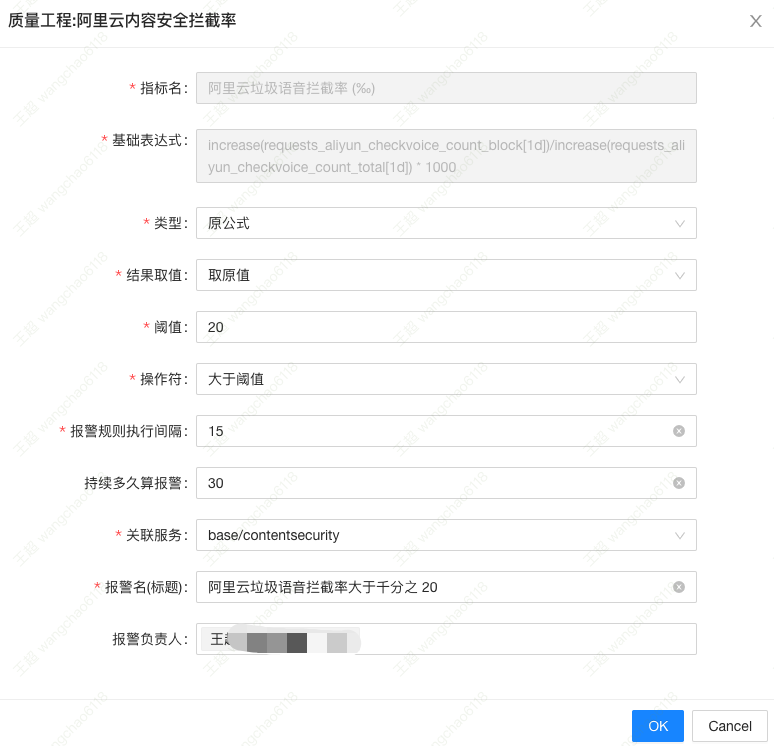
如图,选择「报警类型」,填写「报警阈值」与「报警负责人」即可,系统会自动下发报警规则。
小结与未来工作
团队在公司的技术框架中进行相关的基础数据建设,打通「调用链」、「日志」、「监控」、「事件」四个维度的可观测性数据,通过设计「交互协议」,固化了「深入挖掘分析」的伴鱼最佳实践。
文中多次提到「调用链日志分析」功能,针对某些未能被采集的 trace_id,该功能则会失效。团队还开发了「模糊调用链日志分析」功能,给定 trace_id 和服务,系统会根据服务的历史依赖关系,
推测本次可能的调用链,构建调用链日志。但,这个历史依赖关系具有时限性,未来团队将引入语言分析,实时构建服务的依赖关系,让系统推测的更准,提高排障效率。