背景
伴鱼智能陪练系统是伴鱼推出的基于 AI 技术的大规模销售人员培训工具,通过配置常见工作场景的工作流,让销售人员与虚拟机器人对话,对话完毕后测评对话的准确性,达到销售新人快速上手的效果,目前通过 SaaS 形式对外提供服务,详情可点击这里。
伴鱼智能陪练系统在使用过程中最大的痛点是语音识别及对话测评过程过慢,导致每次流程流转过程中用户需要等待较长时间,非常影响用户体验。下面主要介绍在语音识别及对话测评方面的技术演进。
语音识别及对话测评 V1.0
在第一版的伴鱼智能陪练系统中,自研 ASR 技术只支持录音文件识别,即用户录音完毕后才能开始进行语音识别,所有交互只能同步进行。语音识别及对话测评的交互如下图所示,主要流程为:
- 用户开始录音
- 用户说完后点击停止录音
- 前端将用户音频文件上传至 OSS 并拿到音频 URL
- 用音频 URL 请求 ASR 服务,获取语音识别结果
- 将语音识别结果展示给用户
- 用户点击提交按钮,用语音识别结果及工作流中配置的标准答案请求测评服务,获取对话测评结果
- 将此对话测评结果展示给用户
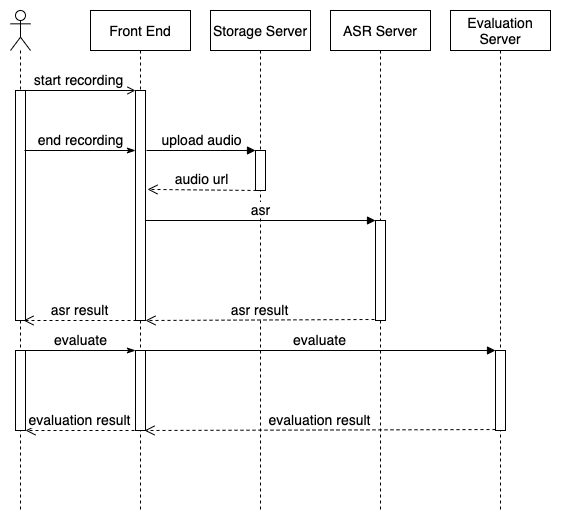
我们看到,在整个交互过程中,直到第 5 步才会第一次给用户展示响应信息,在此之前,一直处于录音 Loading 及 ASR Loading 阶段。伴鱼自研 ASR 的录音文件识别的识别速度大概为 音频时长 / 5,假设用户录 30s 的音频,文件上传至 OSS 需要 0.5s,那么从用户录音开始,共需要 36.5s 左右才能给用户展示语音识别结果,对话测评也需要 2-3s,用户等待时间非常久。
设计方案
目标
通过上述对 V1.0 交互流程的分析,主要问题在于,录音-语音识别-对话测评过程中用户等待时间过长,流程流转不流畅,难以达到模拟真实用户陪练的效果。因此优化的核心目标是:减少用户等待时间,尽量做到用户录音完毕就出结果。
语音识别
对于语音识别,业界除了录音文件识别外,还有提供实时语音识别的能力。实时语音识别是从用户录音开始,就不断发送录音片段至 ASR 服务,ASR 服务不断对音频片段进行解码生成中间结果,最后当用户录音完毕后,只需要把最后一小部分未解码的片段完成解码即可,因此用户等待时间就是最后一小部分音频片段的解码耗时,正常情况在 100ms 左右,用户几乎没有感知。因此,语音识别的优化需要提供自研实时语音识别能力。
对话测评
对话测评有很多维度,主要可分为两大类:录音维度和文本维度。
录音维度包括用户发音质量(用户说话是否发音标准)和录音质量(录音是否清晰无噪音),其中用户发音质量在语音识别中可以一起进行,需要单独处理的是录音质量。V1.0 中录音质量是拿到用户完整音频后计算得出,计算速度与音频长度成正比,因此用户录音时间越长,等待时间越久。优化的第一种方案是类似实时语音识别,通过边读边测评录音质量来减少用户最后等待时间;第二种方案是利用采样的思想,只取前 10s 音频来反映整体的录音质量。考虑到人力成本,相较第一种方案,第二种方案只需要 2% 左右的投入就可以达到 70% 左右的效果,并且测评效果可以通过改善采样方式继续提升,因此我们决定采用第二种方案。
文本维度是通过 NLP,来测评用户对话的完整度、流畅度、是否礼貌用语、是否命中关键词等。此维度的速度提升只能优化算法,优化难度较大。考虑到人力成本,我们采用异步交互的方式优化,前端异步进行录音和文本维度的测评,语音识别完成后便进入下一步流程,异步展示上一步用户回答的分数。
整体流程
优化后的语音识别及对话测评的交互过程如下图所示,新的交互流程如下:
- 用户开始录音,前端跟 ASR 服务端建立连接
- ASR 服务端初始化完成,与前端完成连接
- 前端发送音频片段至 ASR 服务端
- ASR 服务端累积到一定音频长度后对音频解码,返回语音识别结果,前端向用户展示中间结果
- 不断重复 3 4 步
- 用户说完话后点击停止录音,前端向 ASR 服务端发送录音完成信号
- ASR 服务端解码剩余音频,返回最终语音识别结果,前端向用户展示最终结果
- ASR 服务端将完整音频上传至 OSS,返回音频 URL 至前端
- ASR 服务端与前端各自断开连接
- 前端用语音识别结果及工作流中配置的标准答案异步请求测评服务
- 测评服务返回测评结果至前端,前端给用户异步展示测评分数
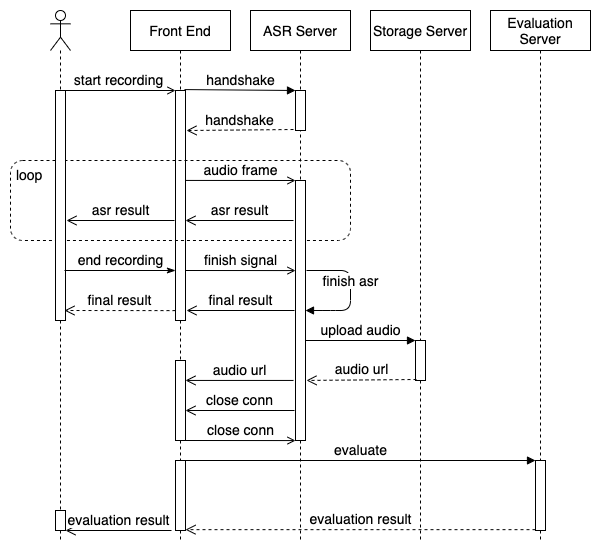
总体来看,虽然整体交互流程变长变复杂了,但从第 4 步开始就给用户实时展示识别结果,用户刚开始说话就能看到说话内容,第 7 步给用户展示最终结果,此时距用户完成录音只有数百毫秒延迟,之后的步骤均异步进行,用户实际等待时间低于 1s,能够达到我们的设计目标。
实现方案
在 V2.0 的方案中,难点主要在于实时语音识别,下面重点讲述实时语音识别服务化的实现方案。
实时语音识别服务化
与 AI 程序交互
要实现实时语音识别,需要 ASR 服务端调用 AI 程序完成(此过程为进程内调用)。AI 程序提供的实时语音识别方法如下:
1 | class ASR { |
要实现实时语音识别,需要每次接收到固定时长音频后调用 AcceptWaveform 方法,让 AI 程序解码出中间结果,音频全部接收完后再调用 FinalResult 方法获取最终结果。
AI 程序有如下限制:
- 每个 ASR 对象(ASR 类实例化的对象)每次只能处理单个语音识别的音频流
- 每次调用
AcceptWaveform传入的data的顺序必须跟实际音频流数据一致
因此,要实现实时语音识别,服务端需要做如下保证:
- 单个实时语音识别的所有音频数据需要交由同一个 ASR 对象处理
- 服务端需要按照客户端发送顺序将音频片段传递给 ASR 对象
网络协议选择
要为前端提供实时语音识别能力,重点在于选择网络协议。可供选择的应用层协议主要为 HTTP 和 WebSocket。
最简版的服务端部署架构如下图所示,在业务服务之前有一层 Nginx 作为反向代理,处理与前端的连接。下面我们会基于此部署架构来分析 HTTP 和 WebSocket 协议的优劣。

HTTP 协议
对于 HTTP 协议,首先要考虑是否使用长连接。如果前端不使用长连接,那么与服务器的交互都是基于不同的 TCP 连接,无法直接利用传输层保证数据的顺序性,需要实现复杂的编码才能保证音频按顺序接收,因此 HTTP 协议需要使用长连接。
建立长连接需要在 Header 中添加 Connection: keep-alive,而 Connection 在 HTTP 协议中是逐跳 (hop-by-hop) 的请求头,只在单个传输层的连接上有意义,因此客户端是与 Nginx 服务器建立了长连接。不过我们可以配置 Nginx 与被代理的 ASR 服务也建立长连接,客户端同一个语音识别请求携带相同的 Key 来让 Nginx 路由到同一个 ASR Server,这样可以模拟达到客户端与 ASR 服务端建立长连接的效果。此时,我们可以做到让音频数据按顺序到达 ASR 服务端。但对于 HTTP 程序,应用层读取传输层数据的文件描述符是由 HTTP 框架控制的,HTTP 框架通常对于每个请求会新创建一个线程或者从线程池中取出一个空闲线程来处理,我们无法直接让同一个线程顺序地读取来自一个 TCP 连接的音频数据,还是要通过额外的编码来保证音频数据的顺序性。
因此,从上述分析来看,对于 HTTP 协议,无论是否使用长连接,我们都最多只能做到让同一个语音识别的数据发送到同一个 ASR 服务的实例上,而音频数据实际会由不同线程接收,需要至少做到以下几点才能符合 AI 程序的要求:
- 每个实时语音识别需要添加一个唯一标识
- 单个语音识别的每个音频片段需要添加 sequence number 来标记其顺序
- 单个语音识别的所有音频数据需要按照 sequence number 顺序放到线程间共享存储中
另外,客户端需要不断接收 ASR 中间结果,因此还要利用长轮询或者 Streaming 的方式从 ASR 服务端获取中间结果。
WebSocket 协议
对于 WebSocket 协议,它是基于单个 TCP 连接的客户端和服务器可以双向通信的应用层协议。首先利用 HTTP Get 请求携带 Upgrade 请求头与服务端握手并建立连接,服务端返回 101 状态码后双方完成连接,并将应用层协议升级为 WebSocket,之后双方便可以基于单个 TCP 连接进行通信。因此,由于 WebSocket 协议在设计之初就是基于单个 TCP 连接通信的,WebSocket 程序读取到的数据都是有序的,无需额外的编码就能达到 AI 程序的要求。
不过在我们的部署架构下,WebSocket 也会由于 Nginx 存在有一定问题。第一,Upgrade 也是逐跳的请求头,无法直接由 Nginx 传递至 ASR 服务,需要添加以下配置,让 Nginx 将 Upgrade 请求头传递给 ASR 服务端;第二,客户端是与 Nginx 建立的 TCP 连接,Nginx 再与 ASR 服务端建立 TCP 连接,要达到 WebSocket 是基于单个 TCP 连接的要求,需要两个 TCP 连接能够一一对应。为此 Nginx 从 1.3.13 版本对 WebSocket 做了特殊处理,当客户端和被 Nginx 代理的服务端完成 WebSocket 握手后,Nginx 会和握手成功的服务端建立专用的网络通道,后续该 WebSocket 连接传递的消息都会通过该通道发送给对应的服务端,这样就达到了 WebSocket 协议的要求。
1 | // Nginx 转发 Upgrade 请求头的配置 |
综上所述,在我们的部署架构下可以使用 WebSocket 协议,基于 WebSocket 协议获取的音频数据直接就是有序的,无需额外编码。并且 WebSocket 协议支持双向通信,服务端可以主动推送消息至客户端,客户端也可以有序地拿到 ASR 中间结果。因此,我们选择基于 WebSocket 协议实现实时语音识别。
模块设计
选择好了网络协议,便可以基于网络协议特性完成系统的设计与实现。系统的模块设计如下图所示:
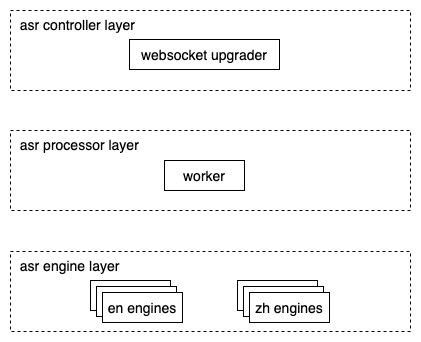
实时语音识别的执行实际由 AI 程序完成,即由我们上文提到的 ASR 对象处理。每个 ASR 对象只能处理单个语音识别,要达到较高的并发,需要初始化多个 ASR 对象。Engine 层负责初始化和管理 ASR 对象,图中的 Engine 代表 ASR 对象。系统在设计上希望支持不同类型的 ASR,因此 Engine 层包含中文 ASR(zh engines)、英文 ASR (en engines)等。
在 WebSocket 协议中,第一步是要握手完成协议升级。Controller 层负责完成握手,他接收 HTTP Get 请求,并将协议升级为 WebSocket,升级完成后便接管了该连接对应的 Socket。之后便初始化一个 Worker,并将 Socket 交给 Worker,由 Worker 负责读写数据。
Worker 负责处理 WebSocket 的数据传输并调度 Engine 进行实时语音识别。首先,Worker 会读取客户端传递的数据,由于 WebSocket 连接基于单个 TCP 连接,此时读取到的数据就是客户端有序发来的音频数据;其次,Worker 会将接收到的音频数据先缓存在内存中;然后,Worker 拿到空闲的 Engine,将音频传递给 Engine 进行实时语音识别;之后,Worker 将中间结果推送至客户端;最后,语音识别完成后,Worker 将音频数据转码并上传至 OSS,再将音频链接推送至客户端。其中,第二步音频缓存的目的有以下几点,第一,Engine 的数量是有限的,无法保证直接就能获取到空闲的 Engine,缓存可以让 Worker 等待空闲 Engine;第二,客户端发送的音频片段大小与 Engine 每次需要接收的音频片段大小不一定一致,缓存可以为音频数据提供缓冲;第三,服务端最后需要将音频上传至 OSS,需要有全量音频数据。
优化效果
优化前

优化后