背景介绍
在发音评测中,如果一个单词中某个音素读错了,比如apple[ˈæpl]中的p读错了,我们怎么反馈给用户,一般是在其对应的字母里标红如apple,这就引出了一个问题已知一个单词和它对应的音标,如何得到每个音标对应的字母。如apple[ˈæpl] 中a:æ pp:p l:l e不发音
算法介绍
- 算法路线
- 深度搜索
- 多序列对齐问题
深度搜索
深度搜索思路:找到48个元音和辅音对应的常用的字母组合,将音标依次按常用的字母组合展开,当完全展开成单词或者剩余为e的情况停止
算法示例:
work[wɜːk]
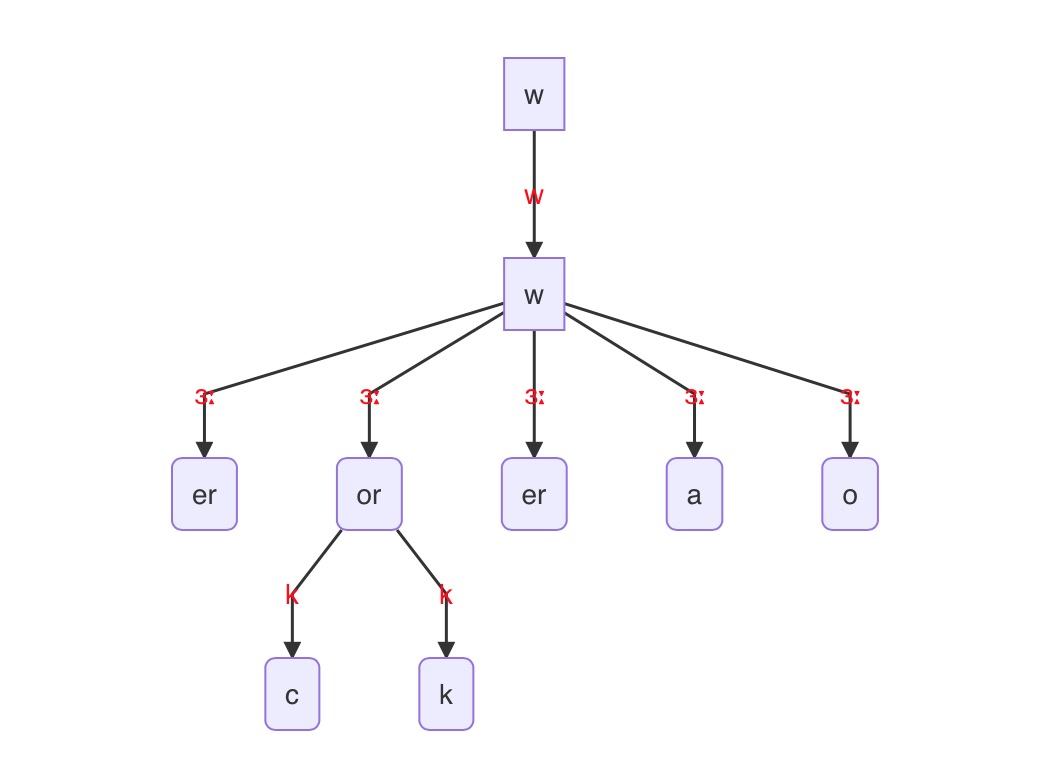
缺点:当出现开头有字母不发音如honor和多条路径时,只会选择最先搜到的,不一定最合适
多序列对齐问题
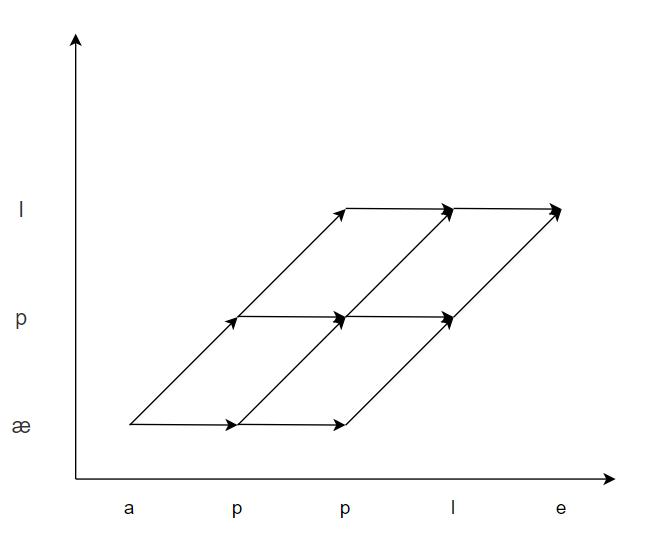
多对多问题,如果不考虑字母不发音的情况,其实是在上图中选出一条概率最大的路径,而考虑字母不发音的情况也只是把路径扩大一些,深度搜索的问题在于每条边的概率都为1,而实际情况不是如此。
问题建模
问题1:如果有了对齐结果我们能计算出 给定字母组合属于给定音素的概率吗?
问题2:如果有所有字母组合属于所有音素的概率表,我们能计算出一个单词的对齐结果吗,也就是计算出最大概率的路径?
问题1的答案是可以的具体公式比如说字母a发æ的概率P(æ|a)
$$
P(æ|a)= \frac{count(æ,a)}{count(a)}
$$
问题2的答案也是可以的,拿apple为例,就是将上图每个可能路径的概率相乘,取最大路径
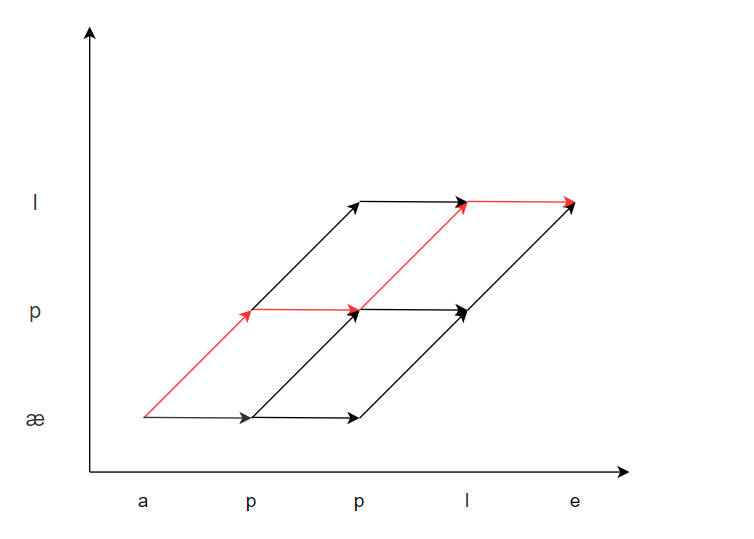
上面红线路径的概率计算公式如下,其他每条概率都可以按这样的公式计算取出最大值
$$
P=P(æ|a)P(p|pp)P(l|l)*P(null|e)
$$
现在最大的问题是我们既没有对齐结果,也没有每对字母组合的发音概率分布,对于这种问题2求解依赖问题1,问题1求解依赖问题2,我们一般采用em迭代模型
em算法
最大期望算法(Expectation-maximization algorithm,又译为期望最大化算法),是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐性变量。
第一步是计算期望(E),利用对隐藏变量的现有估计值,计算其最大似然估计值;
第二步是最大化(M),最大化在E步上求得的最大似然值来计算参数的值。M步上找到的参数估计值被用于下一个E步计算中,这个过程不断交替进行
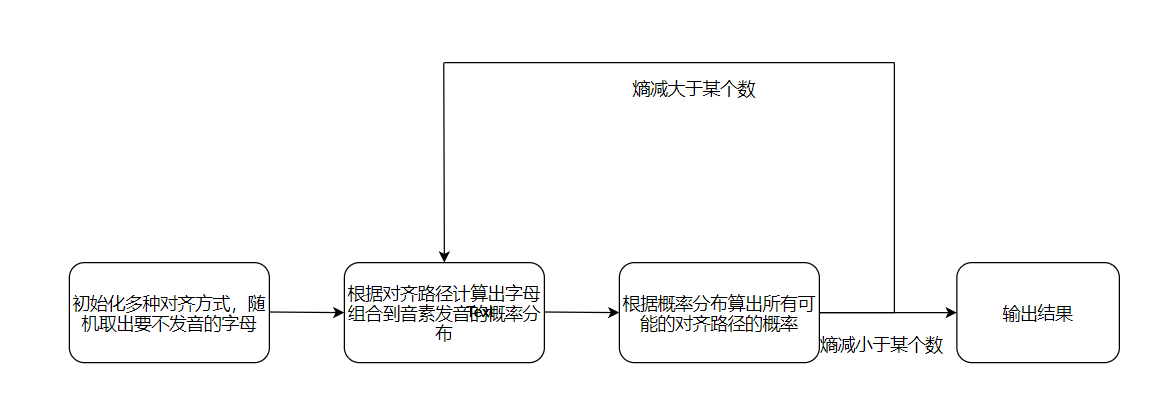
该问题具体化:
第一步是计算期望(E):根据已有的字母的发音概率分布,求出所有可能单词对齐路径的概率
第二步是最大化(M):根据对齐路径概率,计算字母的发音概率分布
循环如此,知道熵的变化小于某一给定值
算法流程
结果
算法结果没有经过系统性评价,粗略的看没有大问题
SIX
[‘S’, ‘I’, ‘X’]
[‘S’, ‘IH’, ‘K:S’]
HONOR
[‘H’, ‘O’, ‘N’, ‘O:R’]
[‘_’, ‘AA’, ‘N’, ‘ER’]
six honor apple 等比较难的词都给出了正确的对应关系
具体自己和有道少儿英语对比相同度到达90%以上,具体效果得老师使用
参考
- github: m2m-aligner
- Letter-Phoneme Alignment: An Exploration